ChatGPT和百度文心一言的区别——文心一言
近日,AI技术公司OpenAI推出了自己的GPt-3模型,并且在纽约召开发布会,向全球首次亮相这一最新、也是目前预测准确率最高的大规模语言生成模型。值得一提的是,与此同时,另一家中国公司Baidu(简称:百度)旗下以知识增强大语言模型“文心一言”为基础研发的若来引擎(即将改名:ERNIE Bot)也正式开源。业内人士认为,这是百度抢占先机,加速产业级应用落地的重要举措。
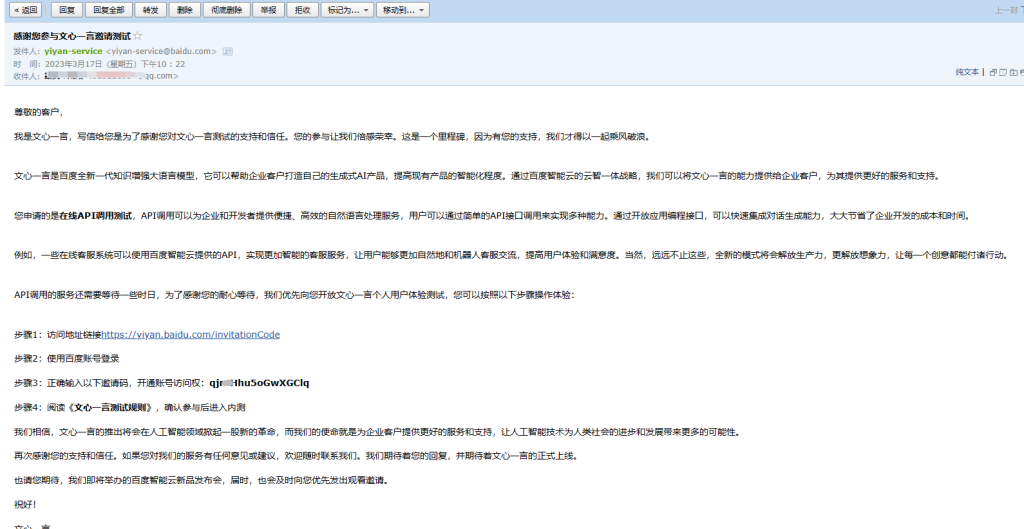
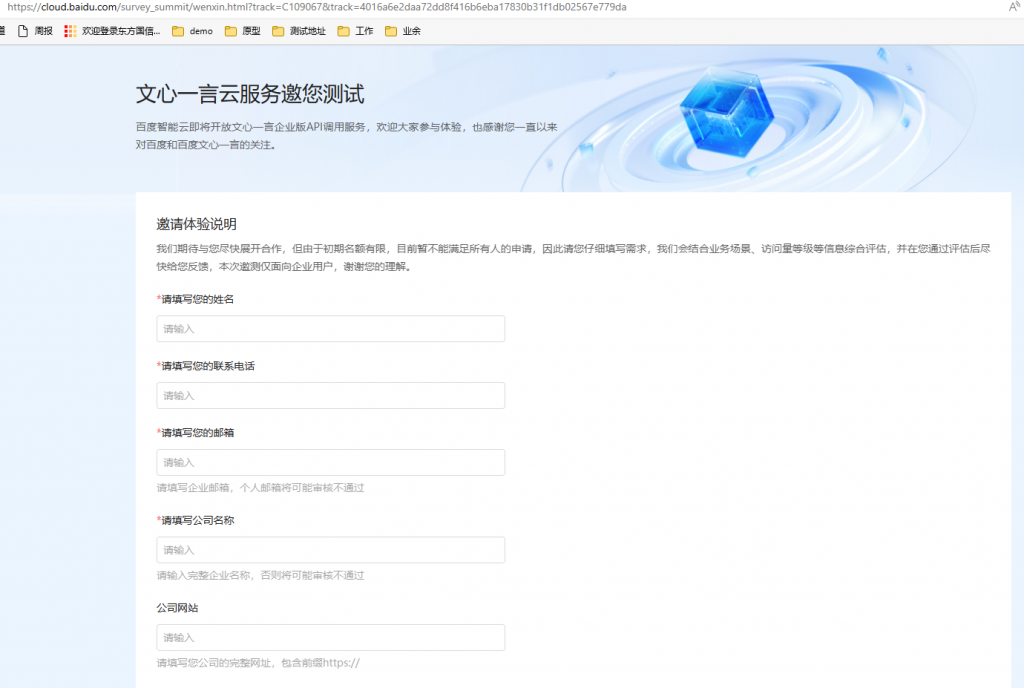
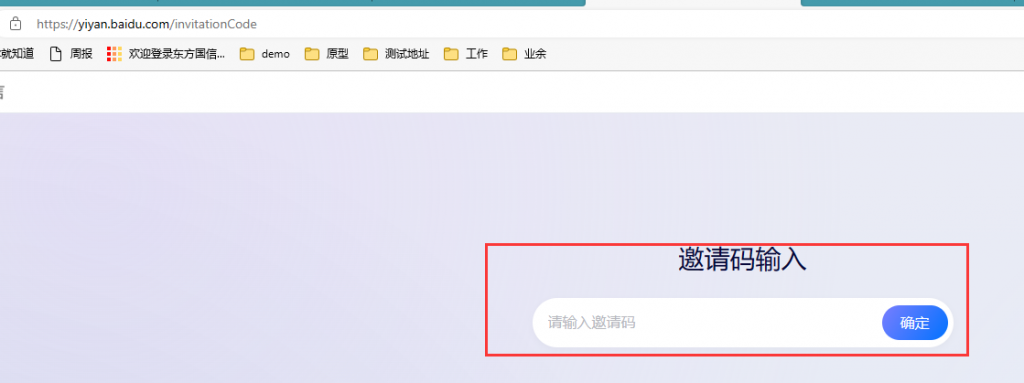
很快,百度文心一言就“分流”了部分功能,转向了对外开放,包括但不限于数学计算器、图片生成等。而今天,我们将要聊的话题,正是关于百度文心一言的代表作——【文心一言】(Wenxin Yiyan),它背后那些鲜为人知的故事。
文心一言的前世今生
2017年底,随着王海峰博士的加入,百度深耕知识增强领域的决心愈加明确。彼时,行业内已经有许多竞品,如 TensorFlow 2.0版本号都已经问世。面对如此激烈的市场环境,王海峰带领的团队并未被吓倒,反而信心满满。
为什么选择文心一言作为突破口呢?原因有两个。一方面,文心一言在2016年就已经实现了从二元门到循环神经网络(RNN)的飞跃,通过参数优化和结构设计,性能已经达到甚至超过其他主流框架;另一方面,文心一言所处的领域——商业智能,具有广阔的市场空间和应用前景。
2017年12月,第一个真正意义上的文心一言模型诞生,它能够理解中文指令,进行文本生成、命名实体识别、检索摘要、情感分析等任务。2018年,文心一言模型的英文翻译「Wise One」正式上线,这也是当时唯一一个支持中英互译的文心一言模型。
截至目前,文心一言在20余种任务上保持state of the art绩效,50+ top1%精顶手稿贡献者,140篇论文/报告/CVPR/ECCV融资总额接近4000万美元。而在2021Q2季度,根据官方披露的数据,文心一言单位价值量较去年同期增长100%,涨幅稳居tokenSummit·2022·秋季榜TOP10 China Token Products(中国权益类初创项目)第一名。
究其根本,文心一言的成功离不开其独特的技术架构和强大的知识增强能力。在架构方面,文心一言使用双层卷积神经网络作为输入层,再利用Transformer注意力机制将序列标签转化为词嵌套,最后通过统计编码器(TCC)将隐藏状态编码为概率分布。这样的架构使得文心一言可以更好地捕捉汉语的复杂语法结构和上下文信息,从而生成更加合理的文本。
除了架构,文心一言的另一个核心优势是知识增强能力。这种能力基于百度完备的知识图谱,通过训练大规模的丰富的跨模态知识图谱,文心一言可以理解上下文信息、做出更加符合语境的判断。